
Extraction des Offres d’Emploi avec Python : Guide Étape par Étape pour Débutants
Découvrez comment utiliser Python pour automatiser l'extraction d'offres d'emploi et optimiser votre recherche d'emploi grâce à des techniques de data science.
Si vous souhaitez échapper aux tâches manuelles répétitives et accéder facilement aux informations les plus récentes sur le marché du travail, le scraping d’annonces d’emploi avec Python vous offre une solution évolutive. Que vous vouliez identifier des leads, suivre les tendances d'emploi ou créer une base de données, ce guide vous permettra de vous exercer concrètement.
En explorant l’extraction de détails d’annonces, vous rencontrerez des défis communs comme la pagination, le contenu chargé par AJAX et les CAPTCHA. Tous ces aspects seront développés dans des guides avancés. Cependant, à la fin de ce tutoriel, vous aurez un script Python opérationnel pour automatiser l'extraction de données d'emploi, depuis le téléchargement du HTML jusqu'à la sauvegarde dans un format pratique (ex. CSV).
Prêt à commencer ?"
Pré-requis
Il n'est pas nécessaire d'être développeur pour extraire des offres d'emploi avec Python. Assurez-vous toutefois de disposer des éléments suivants :
• Compétences informatiques de base : savoir gérer des fichiers et naviguer dans votre système.
• Notions de ligne de commande : une compréhension de base du terminal ou de l'invite de commande sera utile pour installer Python et ses bibliothèques.
• Un ordinateur connecté à Internet : nécessaire pour télécharger Python et les outils associés.
Étape 1 : Configuration de l’environnement et du projet
Voici un aperçu rapide de l’installation de Python selon les différents systèmes d’exploitation et des recommandations pour choisir la version appropriée :
1.1 Installation de Python en fonction de votre système d’exploitation
Il est recommandé d’utiliser Python 3.8 ou une version plus récente, car le support de Python 2 a été interrompu. Pour la majorité des utilisateurs, la dernière version stable de Python 3 est le meilleur choix.
Installer Python sous Windows
- Accédez au site officiel de Python et téléchargez la dernière version de l'installateur Python 3 pour Windows.
- Lancez l'installateur et cochez l’option "Add Python to PATH" (ajouter Python au PATH), c'est essentiel.
- Cliquez sur "Install Now" et suivez les instructions à l'écran.
- Une fois l’installation terminée, ouvrez l’invite de commande Windows PowerShell et entrez la commande suivante pour vérifier l’installation

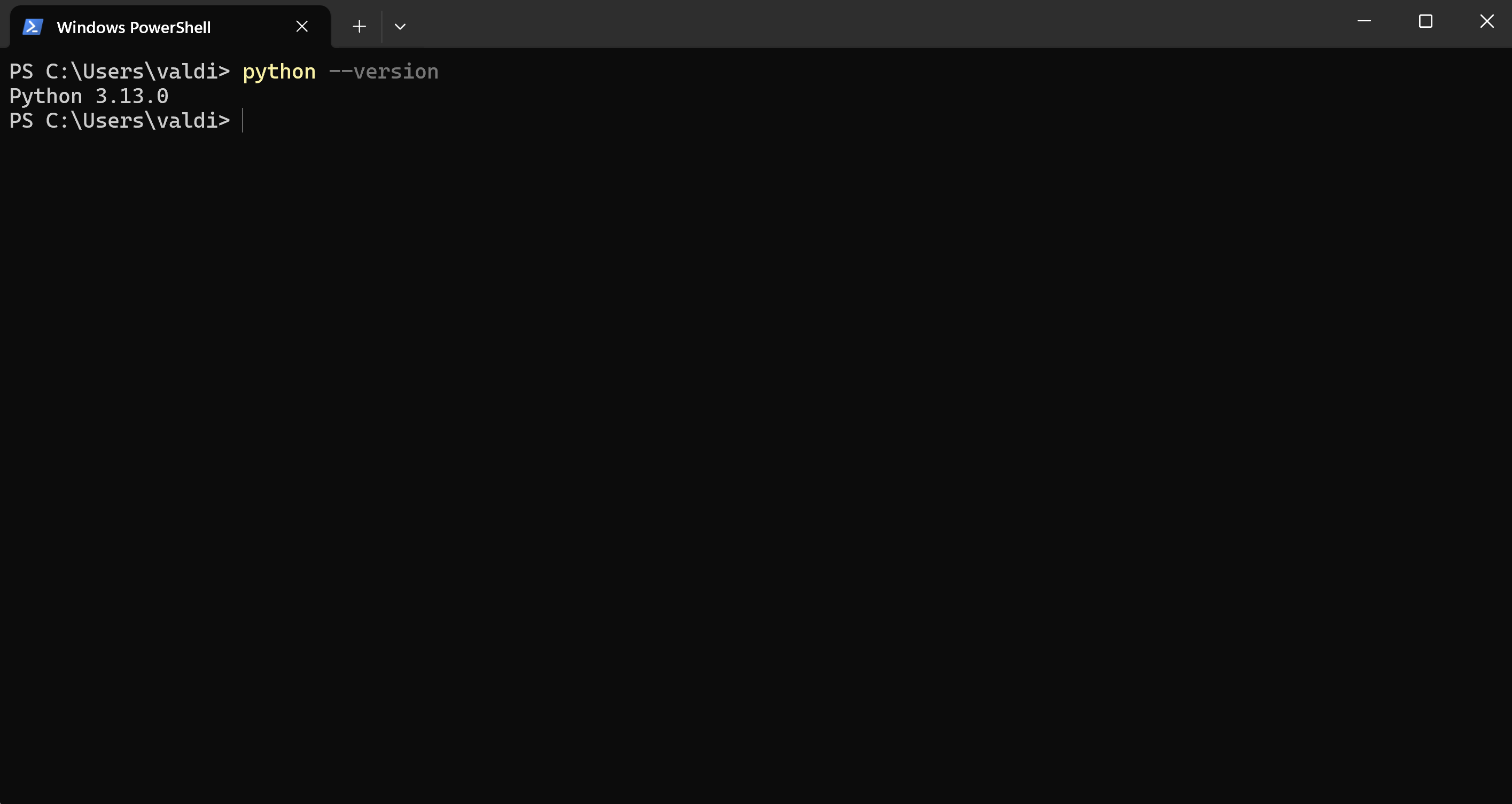
Installer Python sous macOS
- Ouvrez le Terminal et exécutez la commande suivante pour obtenir les outils de développement nécessaires :

- Copier le code
xcode-select --install- Téléchargez l'installateur de la dernière version de Python 3 pour macOS directement depuis le site officiel de Python.
- Cliquez sur "Install Now" et suivez les instructions à l'écran.
- Ouvrez le fichier téléchargé et suivez les étapes d'installation.
- Après l'installation, ouvrez à nouveau le Terminal et tapez la commande suivante pour confirmer l’installation (utilisez "python3" au lieu de "python" car macOS inclut par défaut Python 2) :

Installer Python sous Linux
- Ouvrez un terminal et mettez à jour la liste des paquets avec :

- Pour installer Python 3, exécutez la commande suivante :

- Après l'installation, vérifiez la version installée avec :
Maintenant que Python est installé en fonction de votre système d’exploitation, vous pouvez installer les bibliothèques nécessaires et configurer votre espace de travail.
1.2 Installation des bibliothèques Python nécessaires
Une fois Python installé, vous devrez ajouter quelques bibliothèques essentielles pour réaliser l'extraction d'annonces d'emploi. Ces bibliothèques incluent :
- Requests : Permet d’envoyer des requêtes HTTP et de télécharger des pages web.
- BeautifulSoup4 : Sert à analyser le HTML et à extraire les données.
- Pandas : Utilisé pour enregistrer et manipuler les données extraites dans un format lisible comme le CSV.
Configuration des bibliothèques :
- Ouvrez votre terminal ou invite de commande.
- Exécutez la commande suivante pour installer les trois bibliothèques en une seule étape :

Le message « Successfully installed » apparaitra si tout s'est bien passé.
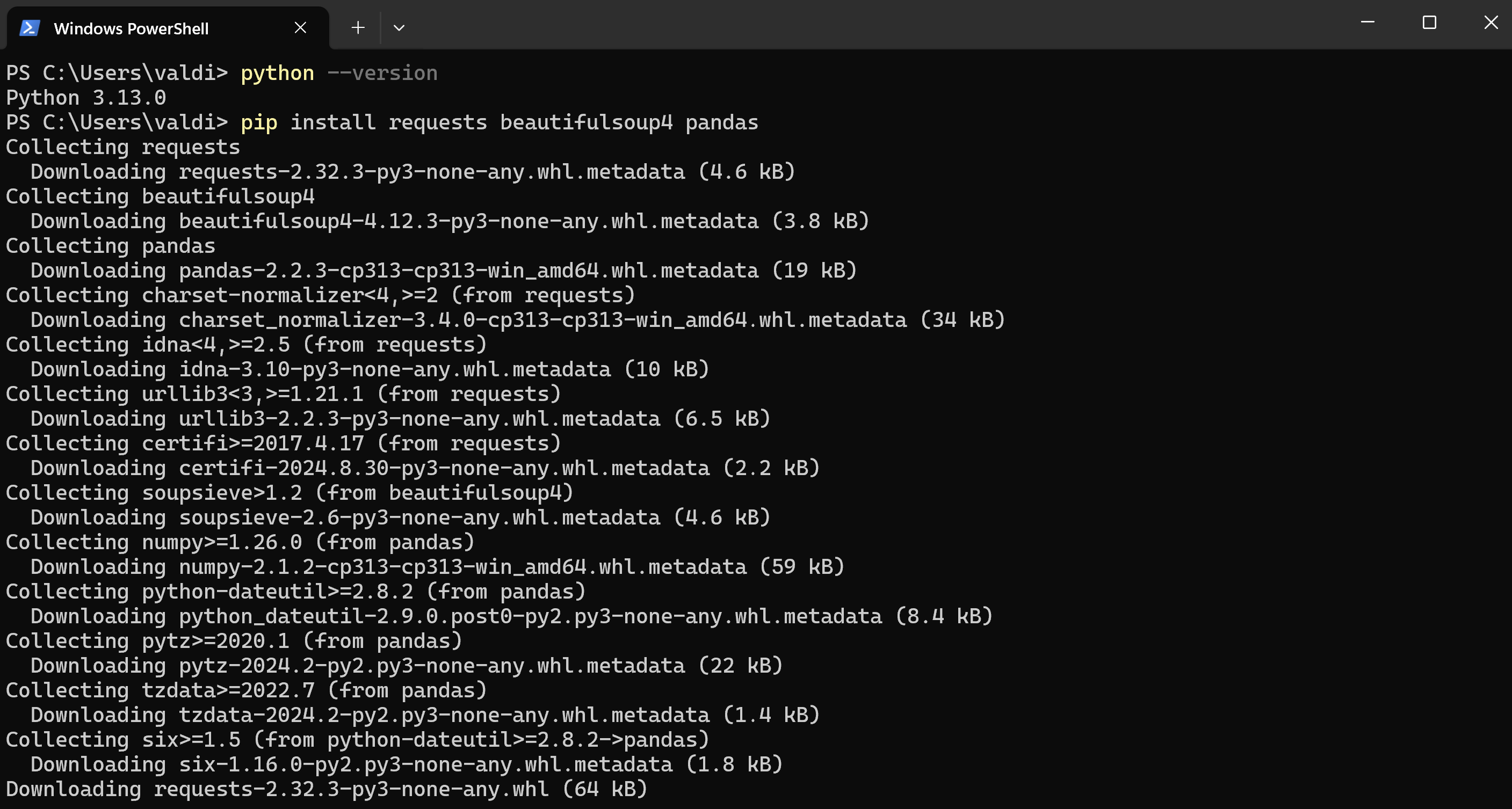
1.3 Préparez votre environnement pour écrire et exécuter le code Python
1.3.1 Ouvrir ou installer un éditeur de texte
Vous aurez besoin d'un éditeur de texte pour écrire votre code Python. Quelques options populaires incluent :
- VS Code (recommandé pour les débutants)
- Sublime Text
- Atom
Vous pouvez également suivre les étapes dans un notebook Google Colab.
1.3.2 Créer un nouveau fichier Python
Dans votre éditeur de texte, créez un nouveau fichier et nommez-le, par exemple, job_scraper_example.py. C’est ici que vous écrirez le code pour votre projet d'extraction d'offres d’emploi.
1.3.3 Importer les bibliothèques
Dans votre fichier Python, commencez par importer les bibliothèques que vous avez installées précédemment. Voici le code à ajouter pour préparer l'extraction d'annonces d'emploi :

1.3.4 Enregistrez votre fichier
Après avoir ajouté les imports, enregistrez le fichier. Vous y ajouterez plus de code au fur et à mesure que vous avancerez dans le tutoriel.
1.3.5 Exécutez le fichier Python
Pour exécuter le fichier Python, ouvrez le terminal ou l'invite de commande dans le répertoire de travail où se trouve votre fichier.
Utilisez la commande cd pour accéder au dossier correct contenant le fichier :
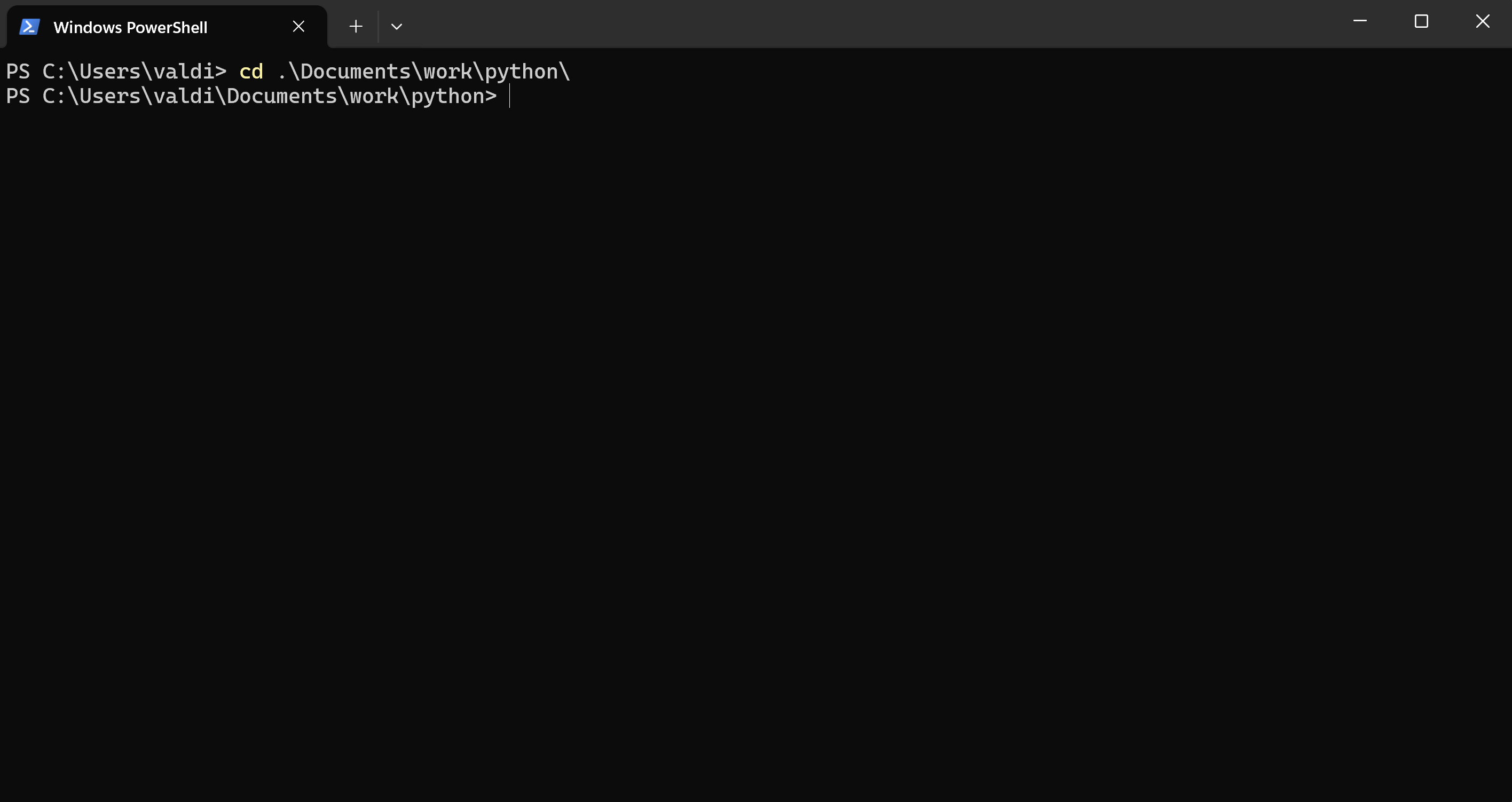
Vous pouvez également faire un clic droit sur le dossier contenant votre script Python, puis sélectionner 'Ouvrir dans un nouveau terminal'.

Exécutez le fichier en tapant :

Si tout est correctement configuré, le code ne générera aucune erreur. Si aucune sortie ne s'affiche pour le moment, c'est normal : vous avez simplement préparé l'environnement et ajouté les bibliothèques.
Étape 2 : Comprendre la Structure des Pages Web
Avant de commencer la collecte de données, il est essentiel de connaître la manière dont les pages web sont construites en HTML. HTML, qui signifie Hypertext Markup Language, est le langage le plus couramment utilisé par les sites web. Les informations des offres d'emploi se trouvent souvent dans différents éléments HTML.
Comprendre la structure d'une page HTML est donc la première étape du processus d'extraction de données.
2.1 Bases de l'HTML
2.1.1 Les Éléments HTML
Les pages web sont constituées de différents éléments HTML, chacun étant délimité par des balises, comme <div>, <h2>, <p>, entre autres. Ces balises définissent l'organisation et la présentation du contenu sur la page, souvent stylisées grâce aux feuilles de style CSS.
Par exemple :
<div>: un conteneur qui peut regrouper d'autres éléments.<h1>à<h6>: des titres classés par ordre d'importance, souvent utilisés pour les titres ou sous-titres (comme le titre de poste).<p>: un paragraphe de texte, qui peut contenir des détails sur un emploi.
Ces balises contiennent souvent des informations clés, comme le titre de l’emploi, le nom de l’entreprise et le lieu, que vous devrez identifier pour l’extraction des données.
En HTML, les éléments ont des attributs, comme "class" et "id", qui aident à structurer et organiser l'information.
2.1.2 Attributs HTML, IDs et Classes
- Classes (class) : Utilisées pour regrouper des éléments similaires, comme les titres de postes :

- IDs : Numéros uniques qui permettent d’identifier des éléments spécifiques.

Ces attributs facilitent la recherche des éléments lors de la collecte de données avec BeautifulSoup en Python.
2.2 Localiser et examiner les données cibles sur les sites d'emploi
Cela nécessite d’analyser le code HTML pour repérer les parties contenant les informations de l’offre. Voici comment procéder :
2.2.1 Ouvrir le site d'emploi dans votre navigateur
Accédez à un site d'emploi, tel qu’Indeed, et ouvrez une page affichant les offres disponibles. Dans cet exemple, nous avons choisi cette page pour le tutoriel --> Indeed
2.2.2 Utiliser les outils de développement pour examiner la page
Faites un clic droit sur n'importe quelle partie de la page et sélectionnez "Inspecter" (ou appuyez sur Ctrl+Shift+I sous Windows ou Cmd+Option+I sur Mac). Cela ouvre les outils de développement du navigateur, où vous pouvez voir comment la page est structurée en HTML.
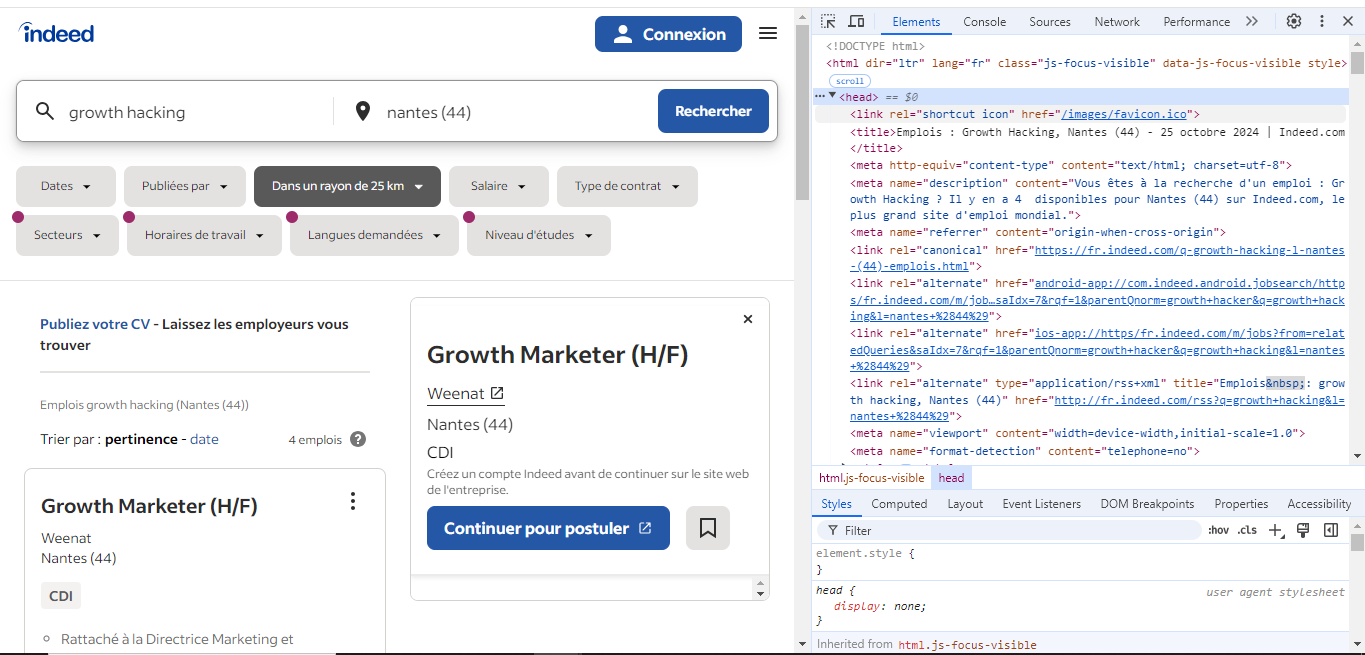
2.2.3 Utiliser les outils de développement pour examiner la page
Une fois les outils de développement ouverts, vous pouvez utiliser l'outil de sélection d'éléments pour repérer rapidement les éléments HTML contenant les données d’emploi souhaitées. Suivez ces étapes :
Dans l'onglet "Éléments" des outils de développement, cliquez sur l'icône en forme de curseur (un carré avec une flèche), généralement située en haut à gauche de la fenêtre des outils. C'est l'outil de sélection d’éléments.
Cliquez ensuite sur la partie de la page contenant les informations que vous souhaitez extraire, comme le titre de l'emploi, le nom de l'entreprise et le lieu. L'élément sélectionné sera mis en évidence dans l'onglet "Éléments", vous montrant précisément la partie du code contenant les données recherchées. Voici un exemple de code avec le titre de poste "Growth Marketer" :
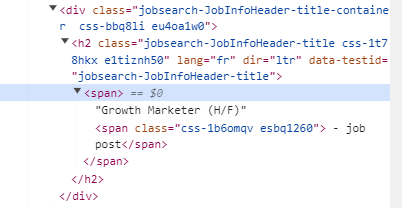
Maintenant, survolez différents éléments de la page avec votre souris. Vous remarquerez que, pour chaque élément survolé, son code HTML correspondant est mis en surbrillance dans le panneau des outils de développement.
Étape 3 : Récupération du contenu HTML avec Requests
3.1 Comprendre les requêtes HTTP : fonctionnement
Lorsque vous accédez à une page web avec votre navigateur, celui-ci envoie une requête HTTP au serveur du site. Ce serveur traite la requête et renvoie le code de la page, souvent en HTML, que votre navigateur utilise ensuite pour afficher la page.
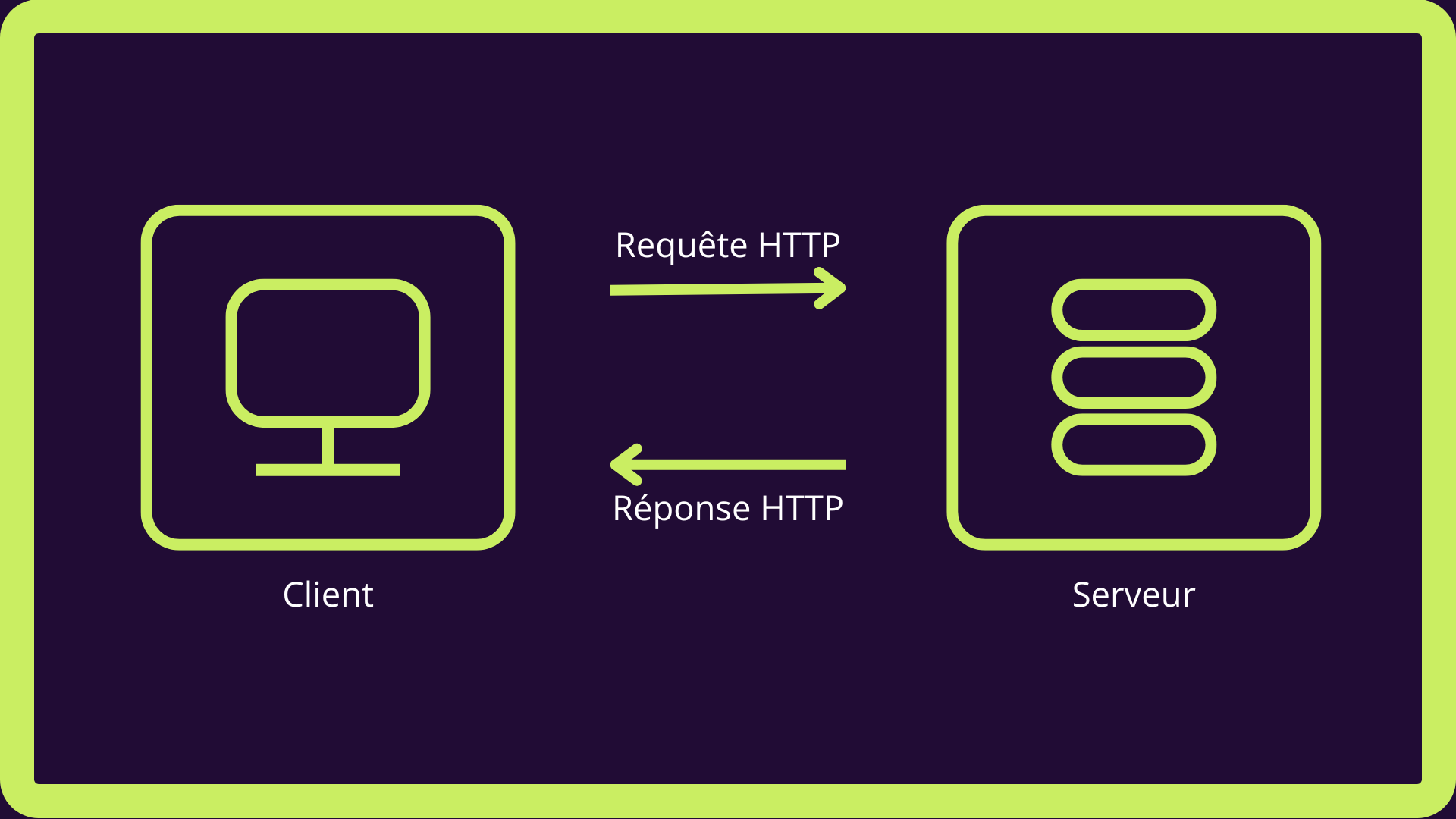
C'est exactement ce qu'on fait en web scraping. Ici, nous utiliserons la bibliothèque Requests de Python pour télécharger le contenu HTML de la page, plutôt que de l'afficher dans un navigateur.
3.2 Récupération du HTML avec requests.get()
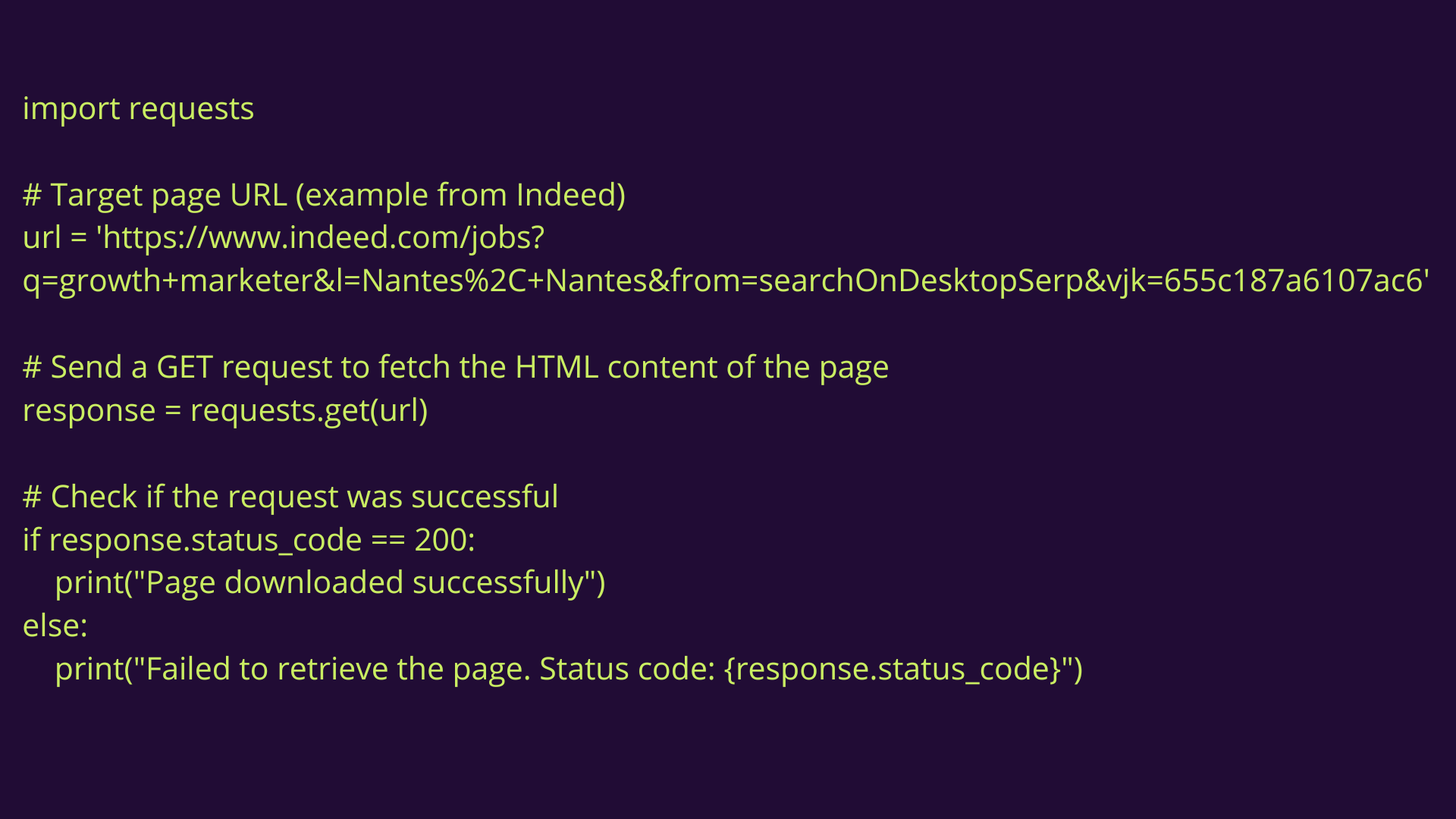
3.2.1 Exemple de code : une requête simple
Tout d'abord, nous allons utiliser requests.get() pour récupérer les informations. Cette commande télécharge le contenu HTML de la page web afin de pouvoir l'utiliser par la suite.
Voici comment procéder :
Si vous exécutez ce code avec l'URL d'Indeed, un statut 403 Forbidden sera renvoyé :

Cela est dû au fait que les plateformes d'emploi comme Indeed ou LinkedIn bloquent l'extraction automatique de leurs données. Le serveur détecte que la requête provient d'un script (ici, la bibliothèque requests de Python) et non d'un navigateur classique.
Les sites d'emploi limitent toujours l'accès pour les clients non-navigateurs afin de protéger leurs données contre les outils d'extraction automatique.
C'est l'un des premiers défis du web scraping : comment contourner ces restrictions ?
3.2.2 Tester Requests avec une autre URL
Ne vous contentez pas de me croire sur parole — testez par vous-même sur un autre site ! Utilisez par exemple un lien de Wikipedia, comme celui-ci :
%2527.png)
Devinez quoi ?
Vous obtiendrez une réponse positive, car Wikipedia n’applique pas le même niveau de restrictions. Cette fois, vous verrez :

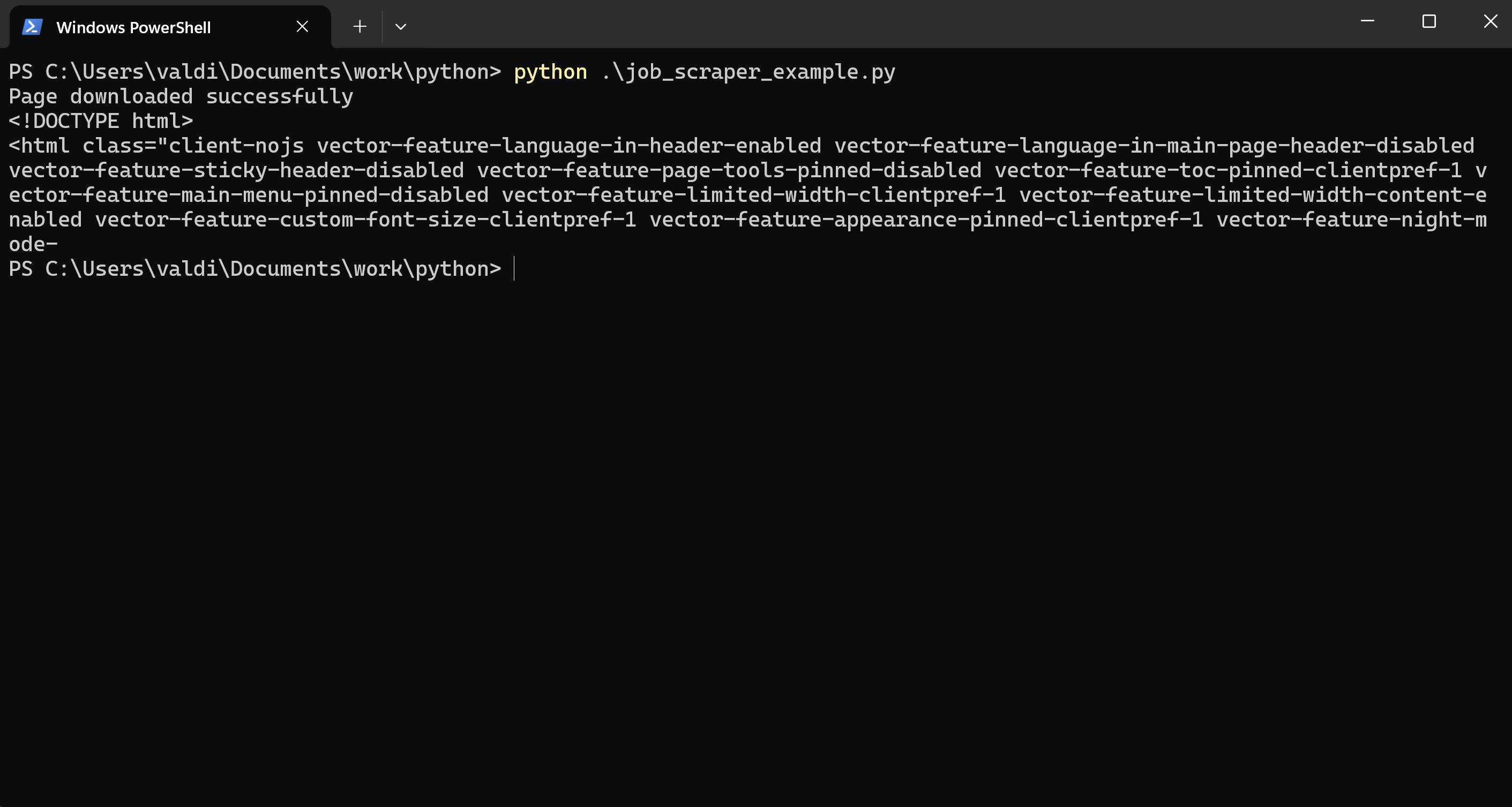
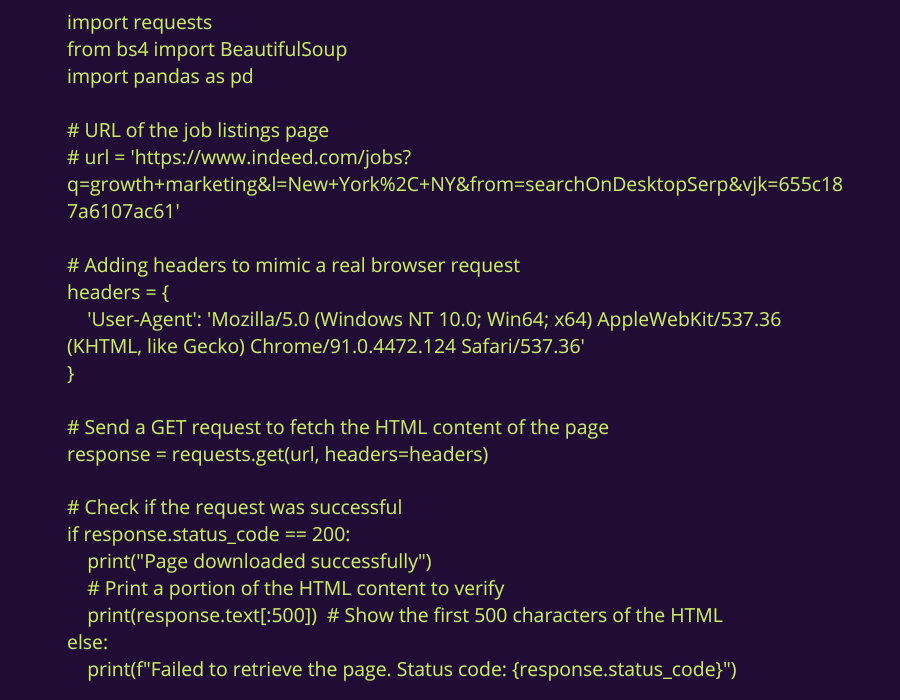
3.3 Contourner les Restrictions du Serveur : Première Méthode pour Récupérer le HTML avec Succès
Une autre méthode pour faire en sorte que notre requête ressemble à celle d’un utilisateur réel est d’ajouter un en-tête User-Agent. Cela fonctionne comme une sorte de carte d'identité indiquant un profil que le serveur reconnaît et accepte.
Cela informe le serveur qu'un navigateur fait la demande, ce qui peut aider à éviter les blocages.
3 signaux d’affaires gratis qui collent parfaitement à votre business ça vous dit ?
Votre domaine est nécessaire pour que nous puissions vous présenter des signaux adaptés à votre entreprise.